1. 背景
存储引擎 是数据库设计的基石。
1.1 数据库存储体系
计算机架构本身具有层级化的存储体系


出于性能、数据量级、数据可用级别等多方面考虑,数据库对存储介质的选项可以分为:
In-MemoryDatabase, 内存数据库Disk-OrientedDatabase, 基于磁盘的数据库
无论是 In-Memory Database 还是 Disk-Oriented Database,都会希望相似的数据组织在一起。
- 对于 Disk-Oriented Database,I/O 是核心的性能瓶颈 (大部分情况)
- 对于 In-Memory Database, CPU Cache Miss 是核心的性能瓶颈
尤其是对于 Disk-Oriented Database,在组织数据时,有两种组织数据的范式:
N-ary Storage Model, 行式存储Decomposition Storage Model, 列式存储
N-ary Storage Model 面向 OLTP 查询并且关注事务一致性, 而 Decomposition Storage Model 面向 OLAP 查询。
- OLTP(Online Transaction Processing): 事务、涉及数据量小、更新频率高、简单查询、ms 级
- OLAP(Online Analytical Processing): 涉及数据量大、聚合/关联、复杂查询、秒级
- HTAP(Hybrid Transaction/Analytical Processing): OLTP、OLAP 的折中
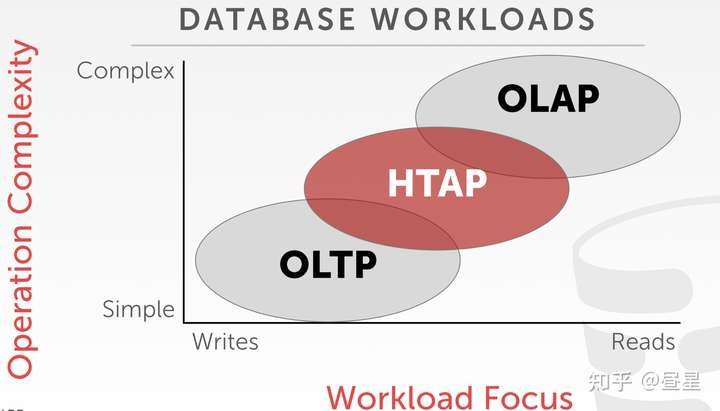
ClickHouse 核心设计目标是尽可能快的执行 Group By 聚合查询,所以 ClickHouse 属于 OLAP 数据库,并且顺其自然,ClickHouse 使用列式存储。
在 OLAP 领域,有几个有一定影响力的项目:
Vertica,VectorWise,MonetDB是早期的列式存储数据库- Google Dremel 是大数据领域实时分析的先驱者
Dremel催生了ParquetParquet同时是数据湖DeltaLake/Iceberg(可选) 的存储底层HBase,Google Bigtable的开源实现,存储单位为 列族Kudu,LSM-Tree(Log-Structured Merge Tree) 存储引擎
而 MergeTree 正是基于 LSM 思想构建的。
1.2 LSM-Tree 存储引擎
简要介绍一下 LSM-Tree (Log-Structured Merge-Tree) 与列式存储相结合时的思想。
- 因为列式存储在写入时需要积攒一定的数据量(写的行数太少体现不出列存优势),因此需要在内存中 Cache 近段时间写入的数据 (
Memory Set),然后再刷写到磁盘 (Disk Set)。 - 想要有比较好的查询性能,需要有一个有序索引,用于
Predicate Pushdown,才可以减少不必要的数据 Scan - 写入磁盘的数据都是局部有序的,因此查询时依然需要对每个存量 Disk Set 进行扫描,随着写入的积累,查询性能会急速下降
- 因此需要定期对磁盘中的
Disk Set进行Merge,增强数据的连贯性,减少碎片。Merge 的过程和数据库执行SortMergeJoin中的 Merge 阶段是非常相似的。
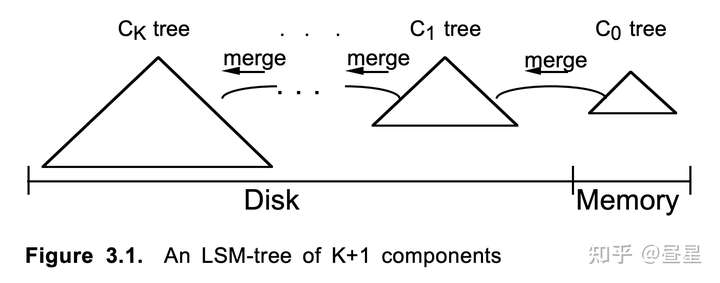
TIPS: LSM-Tree 并非为了列存设计的,LSM-Tree 主要对标 B-Tree,提升写入性能。但是 LSM-Tree 因为需要将数据 Cache 在内存一段时间以及需要定时对数据进行整理,和列存产生了一些共性。
2. MergeTree 概述
ClickHouse 官方有一个关于 MergeTree 引擎工作的分享 Dive into ClickHouse Storage System
这里摘取重点陈述.
2.1 Create Table DDL
CREATE TABLE mt (
EventDate Date,
OrderID Int32,
BannerID UInt64,
UserId String,
GoalNum Int8,
INDEX UserIdIndex (UserId) TYPE bloom_filter GRANULARITY 4
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (OrderID, BannerID)上面是一个 ClickHouse MergeTree 示例, 相比于传统 OLTP 数据库,MergeTree 有以下不同:
- 主键是可以重复的, 默认为
ORDER BY指定的字段,数据会按照主键排序 - 支持分区
2.2 Storage Layout
- 每次写入创建一个目录存储数据 (如 201809_2_2_0)
$ ls /var/lib/clickhouse/data/default/mt
201809_2_2_0 201809_3_3_0 201810_1_1_0 201810_4_4_0 201810_1_4_1
detached format_version.txt- 每个字段单独存放一个文件,如
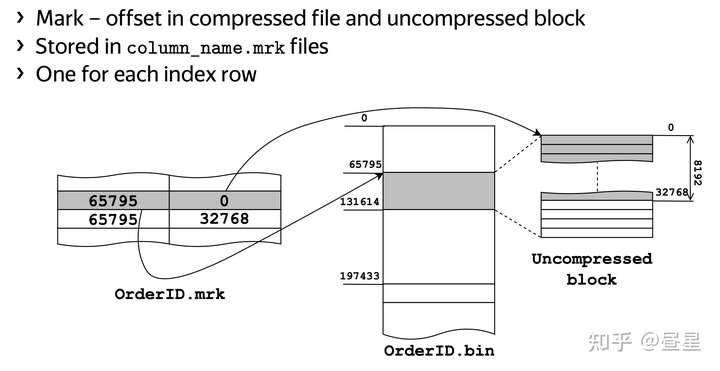
GoalNum.bin,BannerID.bin - 每个字段有一个单独的 Mark 索引, 如
GoalNum.mrk - 对于分区信息,有
partition.dat,minmax_EventDate.idx primary.idx存放主键索引- …
$ ls /var/lib/clickhouse/data/default/mt/201810_1_4_1
GoalNum.bin GoalNum.mrk BannerID.bin ...
primary.idx checksums.txt count.txt columns.txt
partition.dat minmax_EventDate.idx2.3 Index
不同于 B-Tree 和 LSM-Tree 构建索引的方式,ClickHouse 构建了一个非常简单有效的稀疏索引(Sparse Index) primary.idx。
如下, ClickHouse 默认每 8192(8K) 行数据,为主键字段创建一行索引数据。
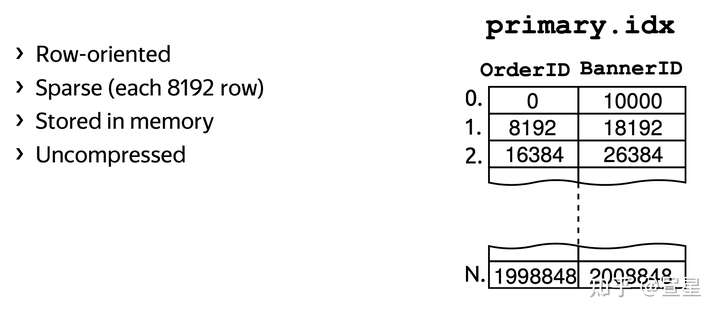
ClickHouse 将 8192 称之为 Index Granularity, 这是一个非常重要的概念。简而言之,Index Granularity 是 ClickHouse 进行数据存储/查询的最小单位。
此外,ClickHouse 为 Column 除了写入 *.bin 数据文件外,还额外建了 *.mrk 索引文件,用于可以快速根据 primary.idx 定位到的 Index 快速定位到 *.bin。简而言之,*.mrk 是 primary.idx 与 *.bin 之间的一座桥。
和 MergeTree Write Path 相关的背景知识介绍到这里,后面开始源码解读部分。
3. MergeTree Write-Path 源码解析
ClickHouse 整体约有 60 余万行 C++ 代码 (仅 src 目录)
~/Documents/master/ClickHouse/src master !17 ?17 ❯ cloc . 00:25:25
4271 text files.
4269 unique files.
25 files ignored.
github.com/AlDanial/cloc v 1.90 T=2.11 s (2019.9 files/s, 368444.2 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C++ 2250 79043 19631 458480
C/C++ Header 1946 44246 22895 150382
CMake 51 304 52 1177
Python 2 66 3 218
SQL 4 0 0 159
Protocol Buffers 1 35 55 107
ANTLR Grammar 1 15 1 105
Bourne Shell 4 20 11 63
Markdown 1 1 0 2
-------------------------------------------------------------------------------
SUM: 4260 123730 42648 610693
-------------------------------------------------------------------------------其中 MergeTree 相关有近 4 万行代码 (src/Storages/MergeTree)
这里不包含 MergeTree Merge 策略相关的代码, Merge 部分的代码实现位于 (src/Processors/Merges)
~/Documents/master/ClickHouse/src/Storages/MergeTree master !17 ?17 ❯ cloc . 00:28:08
225 text files.
225 unique files.
0 files ignored.
github.com/AlDanial/cloc v 1.90 T=0.14 s (1662.5 files/s, 395988.9 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C++ 106 6805 2306 31543
C/C++ Header 117 2789 2005 8139
CMake 2 0 0 5
-------------------------------------------------------------------------------
SUM: 225 9594 4311 39687
-------------------------------------------------------------------------------3.1 MergeTree 代码结构
MergeTree (src/Storages/MergeTree) 主体代码结构如下:
IMergeTreeDataPart, 接口: MergeTree PartIMergedBlockOutputStream, 接口: 序列化输出流IMergeTreeDataPartWriter, 接口: MergeTreeData Part WriterMergeTreeDataPart*, MergeTree Part 的实现,包括 Wide、Compact、In-Memory 多种模式MergeTreeDataPartWriter*, MergeTreeData Part 各种模式的 Writer 实现MergeTreeIndex*, MergeTree 各种 Index 的实现 (min-max, set, bloom-filter …)ReplicatedMergeTree*, Replicated MergeTree 相关- …
3.2 MergeTree Write-Path 整体流程
MergeTree Write 实现位于 MergeTreeSink.cpp, MergeTreeSink::consume().
从 ClickHouse 收到 Insert Query 到达 MergeTreeSink::consume() 经历以下路径:
InterpreterInsertQuery.cpp, InterpreterInsertQuery::buildChainImpl()- auto sink = table->write(…);
IStorage.h, class SinkToStorage- virtual SinkToStoragePtr write(…)
StorageMergeTree.cpp, SinkToStoragePtr StorageMergeTree::write- return std::make_shared(…)
MergeTreeSink.cpp, MergeTreeSink::consume(Chunk chunk)
直入重点,我们从 MergeTreeSink::consume() 开始. 下图为整体写入流程, 其中每个步骤都加了编号 Px.x 方便详解。

3.3 MergeTree Write-Path 源码解析
TIPS 这里的代码会加上笔者自己的注释 源码细节比较多,在文中会省略部分次要代码
P0, MergeTreeSink::consume
void MergeTreeSink::consume(Chunk chunk)
{
auto block = getHeader().cloneWithColumns(chunk.detachColumns());
// 按 Partition By 子句指定的分区,将 block 拆成每个 Partition 一个 Block, block -> []block
auto part_blocks = storage.writer.splitBlockIntoParts(block, max_parts_per_block, metadata_snapshot, context);
for (auto & current_block : part_blocks)
{
Stopwatch watch;
// 每个 Block 创建新的 Part
// 一个 MergeTree 表包含多个 Part, Part 会在后台定期合并 (Merge)
// 新建 Part 时会写到 Temp 目录,以防止查询时读到不完整的写入
MergeTreeData::MutableDataPartPtr part = storage.writer.writeTempPart(current_block, metadata_snapshot, context);
/// If optimize_on_insert setting is true, current_block could become empty after merge
/// and we didn't create part.
if (!part)
continue;
// 挂载 Temp Part 到表空间下
/// Part can be deduplicated, so increment counters and add to part log only if it's really added
if (storage.renameTempPartAndAdd(part, &storage.increment, nullptr, storage.getDeduplicationLog()))
{
// 记录 part metrics 到 system.part_log 表
PartLog::addNewPart(storage.getContext(), part, watch.elapsed());
// 触发后台 Merge 任务
/// Initiate async merge - it will be done if it's good time for merge and if there are space in 'background_pool'.
storage.background_operations_assignee.trigger();
}
}
}
可以看到 MergeTreeSink::consume 主要包含四个步骤:
- P1, 将 Block 按照 Partition 拆成 N 个 Block
- P2, 写入 Part 到 Temp 目录防止
Dirty Read - P3, 将 Temp Part 挂载到表空间下, 这样便可以被客户端查询到数据
- P4, 触发一些后台执行的任务 (例如执行 Merge)
后续对每个步骤分开阐述。
P1, MergeTreeDataWriter::splitBlockIntoParts
BlocksWithPartition MergeTreeDataWriter::splitBlockIntoParts(
const Block & block, size_t max_parts, const StorageMetadataPtr & metadata_snapshot, ContextPtr context)
{
// 省略 ...
// 未分区时, 快速跳过返回
if (!metadata_snapshot->hasPartitionKey()) /// Table is not partitioned.
{
result.emplace_back(Block(block), Row{});
return result;
}
Block block_copy = block;
// executePartitionByExpression 对 Block 执行 MergeTree Partition By 子句, 并且将新增的 key 字段添加到 block_copy 中
// partition_key_names_and_types 仅包含分区相关字段
/// After expression execution partition key columns will be added to block_copy with names regarding partition function.
auto partition_key_names_and_types = MergeTreePartition::executePartitionByExpression(metadata_snapshot, block_copy, context);
ColumnRawPtrs partition_columns;
partition_columns.reserve(partition_key_names_and_types.size());
for (const auto & element : partition_key_names_and_types)
partition_columns.emplace_back(block_copy.getByName(element.name).column.get());
// buildScatterSelector 建立了 row_id -> partition_id 之间的映射
// selector 等价于 []int 类型, selector[row_id] = partition_id
PODArray<size_t> partition_num_to_first_row;
IColumn::Selector selector;
buildScatterSelector(partition_columns, partition_num_to_first_row, selector, max_parts);
// 省略 ...
// IColumn::scatter 算子可以将一个 Column 一拆多
// 对每个 Column 一拆多后,组合为多个 Block
for (size_t col = 0; col < block.columns(); ++col)
{
MutableColumns scattered = block.getByPosition(col).column->scatter(partitions_count, selector);
for (size_t i = 0; i < partitions_count; ++i)
result[i].block.getByPosition(col).column = std::move(scattered[i]);
}
return result;
}
我们看到 splitBlockIntoParts 有下面几个关键步骤:
- P1.1, 通过 executePartitionByExpression() 计算出与 partition 相关的字段 (可能会新增字段)
- P1.2, 通过 buildScatterSelector() 计算出 row 与 partition 之间的映射关系
- P1.3, 通过 IColumn::scatter() 将每个 Column 都完成一拆多, 最终组合为多个 Block
P2, MergeTreeDataWriter::writeTempPart
MergeTreeDataWriter::writeTempPart 是写入的具体实现,我们会详细说明这一部分。
MergeTreeData::MutableDataPartPtr MergeTreeDataWriter::writeTempPart(
BlockWithPartition & block_with_partition, const StorageMetadataPtr & metadata_snapshot, ContextPtr context)
{
Block & block = block_with_partition.block;
static const String TMP_PREFIX = "tmp_insert_";
// 生成一个 Part ID, 每一个新的 Part 插入都会生成一个自增的 Part ID
/// This will generate unique name in scope of current server process.
Int64 temp_index = data.insert_increment.get();
// 计算 partition 相关字段的 min-max 统计
auto minmax_idx = std::make_shared<IMergeTreeDataPart::MinMaxIndex>();
minmax_idx->update(block, data.getMinMaxColumnsNames(metadata_snapshot->getPartitionKey()));
MergeTreePartition partition(std::move(block_with_partition.partition));
MergeTreePartInfo new_part_info(partition.getID(metadata_snapshot->getPartitionKey().sample_block), temp_index, temp_index, 0);
String part_name;
if (data.format_version < MERGE_TREE_DATA_MIN_FORMAT_VERSION_WITH_CUSTOM_PARTITIONING)
{
// 省略, 这里为旧版 MergeTree 格式 ...
}
else
part_name = new_part_info.getPartName();
/// If we need to calculate some columns to sort.
if (metadata_snapshot->hasSortingKey() || metadata_snapshot->hasSecondaryIndices())
// SORT BY toYYYYMM(time) 这种情况需要计算 Expression 的值
data.getSortingKeyAndSkipIndicesExpression(metadata_snapshot)->execute(block);
// 省略 ...
ProfileEvents::increment(ProfileEvents::MergeTreeDataWriterBlocks);
/// Sort
IColumn::Permutation * perm_ptr = nullptr;
IColumn::Permutation perm;
if (!sort_description.empty())
{
// isAlreadySorted 仅对 Block 未排序情况下进行排序
if (!isAlreadySorted(block, sort_description))
{
// stableGetPermutation 为稳定排序(尽可能保持插入顺序), 实现为 std::stable_sort
// 注意这里并未对所有列都进行了排序, 而是建立了原始数据与排序数据 row_id 的映射
stableGetPermutation(block, sort_description, perm);
perm_ptr = &perm;
}
else
ProfileEvents::increment(ProfileEvents::MergeTreeDataWriterBlocksAlreadySorted);
}
// 省略 ...
// updateTTL 更新 TTL 信息, TTL 为 MergeTree 提供的数据生命周期管理功能
// 记录当前 Part 与 TTL 相关字段的 min,max 统计,用于后续方便快速判断一个 Part 是否满足 TTL 条件
for (const auto & ttl_entry : move_ttl_entries)
updateTTL(ttl_entry, move_ttl_infos, move_ttl_infos.moves_ttl[ttl_entry.result_column], block, false);
// 省略 ...
// createPart
auto new_data_part = data.createPart(
part_name,
// 注意 choosePartType 会按照 Block 大小和行数决定是否使用 Compact/Memory 存储方式
data.choosePartType(expected_size, block.rows()),
new_part_info,
createVolumeFromReservation(reservation, volume),
TMP_PREFIX + part_name);
// 省略 ...
SyncGuardPtr sync_guard;
if (new_data_part->isStoredOnDisk())
{
// 省略 ...
// sync_guard 会在析构函数执行时完成目录 Sync 到磁盘
if (data.getSettings()->fsync_part_directory)
sync_guard = disk->getDirectorySyncGuard(full_path);
}
// 省略, 记录额外的 TTL 信息 ...
// [TTL expr
// [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx' [, ...] ]
// [WHERE conditions]
// [GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ]
new_data_part->ttl_infos.update(move_ttl_infos);
/// This effectively chooses minimal compression method:
/// either default lz4 or compression method with zero thresholds on absolute and relative part size.
auto compression_codec = data.getContext()->chooseCompressionCodec(0, 0);
// MergedBlockOutputStream 将 Block 序列化到磁盘
const auto & index_factory = MergeTreeIndexFactory::instance();
MergedBlockOutputStream out(new_data_part, metadata_snapshot,columns,
index_factory.getMany(metadata_snapshot->getSecondaryIndices()), compression_codec);
bool sync_on_insert = data_settings->fsync_after_insert;
// 写入数据主体, Columns / Indexs
out.writeWithPermutation(block, perm_ptr);
// 处理 PROJECTION 字段, PROJECTION projection_name_1 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY])
for (const auto & projection : metadata_snapshot->getProjections())
{
auto projection_block = projection.calculate(block, context);
if (projection_block.rows())
new_data_part->addProjectionPart(
projection.name, writeProjectionPart(data, log, projection_block, projection, new_data_part.get()));
}
// 写入收尾, Checksums、ttl info 等信息
out.writeSuffixAndFinalizePart(new_data_part, sync_on_insert);
// 省略, 添加写入指标 ...
return new_data_part;
}
我们看到 writeTempPart 整体的逻辑还是比较琐碎的,上面已经省略了很多细节,整体来说,分为以下步骤:
- P2.1, minmax_idx->update(…) 对 Partition 涉及的字段统计 min-max 值,作为额外的谓词下推索引
- P2.2, stableGetPermutation() 对 Block 数据按照 Order By 字段排序,这里有两个细节
- 会预先检查是否排序,因此如果数据已经排过序再写入,事实上写入速度会有提升
- stableGetPermutation 为稳定排序, 底层实现为 std::stable_sort,时间复杂度为 O(N((logN)^2))
- P2.3, updateTTL(…) 是为支持 TTL 数据生命周期管理做的数据 min-max 索引,用于快速判断一个 Part 是否命中 TTL
- P2.4, MergeTreeData::createPart 创建 Part 实例
- 注意 choosePartType() 会按照 Block 大小和行数决定是否使用 Compact/Memory 存储方式,默认为 Wide 方式存储
- 本文重点讨论 Wide (即列式) 存储方式
- P2.5, MergedBlockOutputStream::writeWithPermutation, 实现 Block 数据的写入
- 后文详细介绍这一部分
- P2.6, MergedBlockOutputStream::writeSuffixAndFinalizePart, 进行一系列的收尾工作
- 统计各个文件的 checksum,写入到
checksums.txt,所有文件的 checksum 记录到一个文件 - 写入 TTL info 信息,写入到
ttl.txt - 写入 Part 总行数写入到
count.txt - 所有字段信息写入到
columns.txt
P2.5, MergedBlockOutputStream::writeWithPermutation
代码清单: src/Storages/MergeTree/MergedBlockOutputStream.cpp
void MergedBlockOutputStream::writeImpl(const Block & block, const IColumn::Permutation * permutation)
{
// Check 各个列行数相同
block.checkNumberOfRows();
size_t rows = block.rows();
if (!rows)
return;
// 调用具体的 MergeTreeDataPartWriter 实现
// 后文以 MergeTreeDataPartWriterWide.cpp 为例
writer->write(block, permutation);
if (reset_columns)
new_serialization_infos.add(block);
rows_count += rows;
}
- checkNumberOfRows() 做了保底检查,确保各个 Column 的行数是相同的
- writer->write(block, permutation) 调用之前 data.createPart() 决定的 Writer 实例
- 可能是 MergeTreeDataPartWriterWide、MergeTreeDataPartWriterCompact、MergeTreeDataPartWriterInMemory 中的一个
- 细节见
MergeTreeData::choosePartType, src/Storages/MergeTree/MergeTreeData.cpp - 后文以 MergeTreeDataPartWriterWide 举例
P2.5.2 MergeTreeDataPartWriterWide::write
代码清单: src/Storages/MergeTree/MergeTreeDataPartWriterWide.cpp
void MergeTreeDataPartWriterWide::write(const Block & block, const IColumn::Permutation * permutation)
{
/// Fill index granularity for this block
/// if it's unknown (in case of insert data or horizontal merge,
/// but not in case of vertical part of vertical merge)
// 在插入数据是,compute_granularity 默认为 true
// index_granularity 含义见第二节的介绍
if (compute_granularity)
{
// 计算出此 Part 对应的 index_granularity
size_t index_granularity_for_block = computeIndexGranularity(block);
// 省略 ...
// 根据 index_granularity_for_block,计算每个 granular 对应的 row 范围
fillIndexGranularity(index_granularity_for_block, block.rows());
}
Block block_to_write = block;
auto granules_to_write = getGranulesToWrite(index_granularity, block_to_write.rows(), getCurrentMark(), rows_written_in_last_mark);
auto offset_columns = written_offset_columns ? *written_offset_columns : WrittenOffsetColumns{};
Block primary_key_block;
if (settings.rewrite_primary_key)
primary_key_block = getBlockAndPermute(block, metadata_snapshot->getPrimaryKeyColumns(), permutation);
// 将所有 Column 排序
Block skip_indexes_block = getBlockAndPermute(block, getSkipIndicesColumns(), permutation);
auto it = columns_list.begin();
for (size_t i = 0; i < columns_list.size(); ++i, ++it)
{
auto & column = block_to_write.getByName(it->name);
if (data_part->getSerialization(*it)->getKind() != ISerialization::Kind::SPARSE)
column.column = recursiveRemoveSparse(column.column);
if (permutation)
{
if (primary_key_block.has(it->name))
{
const auto & primary_column = *primary_key_block.getByName(it->name).column;
writeColumn(*it, primary_column, offset_columns, granules_to_write);
}
else if (skip_indexes_block.has(it->name))
{
const auto & index_column = *skip_indexes_block.getByName(it->name).column;
writeColumn(*it, index_column, offset_columns, granules_to_write);
}
else
{
/// We rearrange the columns that are not included in the primary key here; Then the result is released - to save RAM.
ColumnPtr permuted_column = column.column->permute(*permutation, 0);
writeColumn(*it, *permuted_column, offset_columns, granules_to_write);
}
}
else
{
// writeColumn 执行最终的写入
// 后文详细说明写入过程
writeColumn(*it, *column.column, offset_columns, granules_to_write);
}
}
if (settings.rewrite_primary_key)
// calculateAndSerializePrimaryIndex 写入主键索引 primary.idx
calculateAndSerializePrimaryIndex(primary_key_block, granules_to_write);
// calculateAndSerializeSkipIndices 写入 Column 对应的二级索引
calculateAndSerializeSkipIndices(skip_indexes_block, granules_to_write);
shiftCurrentMark(granules_to_write);
}
- MergeTreeDataPartWriterWide::write 实现 MergeTree 以 Wide 形式写入
- 首先由 computeIndexGranularity() 计算当前 Block 的 IndexGranularity
- 将所有 Column 按照 Primary key 排序,用的是之前在 writeTempPart() 构造的 permutation
- writeColumn 将每个 Column 分别写入磁盘,后面我们详细介绍这个过程
- calculateAndSerializePrimaryIndex、calculateAndSerializeSkipIndices 写入主键、二级索引
P2.5.3 computeIndexGranularity
代码清单: src/Storages/MergeTree/MergeTreeDataPartWriterOnDisk.cpp
static size_t computeIndexGranularityImpl(
const Block & block,
size_t index_granularity_bytes,
size_t fixed_index_granularity_rows,
bool blocks_are_granules,
bool can_use_adaptive_index_granularity)
{
size_t rows_in_block = block.rows();
size_t index_granularity_for_block;
if (!can_use_adaptive_index_granularity)
// fixed_index_granularity_rows 来自于 Setting 配置 index_granularity
index_granularity_for_block = fixed_index_granularity_rows;
else
{
size_t block_size_in_memory = block.bytes();
if (blocks_are_granules)
index_granularity_for_block = rows_in_block;
else if (block_size_in_memory >= index_granularity_bytes)
{
// 按照 index_granularity_bytes 计算每个 Granular 需要多少行
size_t granules_in_block = block_size_in_memory / index_granularity_bytes;
index_granularity_for_block = rows_in_block / granules_in_block;
}
else
{
size_t size_of_row_in_bytes = std::max(block_size_in_memory / rows_in_block, 1UL);
index_granularity_for_block = index_granularity_bytes / size_of_row_in_bytes;
}
}
if (index_granularity_for_block == 0) /// very rare case when index granularity bytes less then single row
index_granularity_for_block = 1;
/// We should be less or equal than fixed index granularity
index_granularity_for_block = std::min(fixed_index_granularity_rows, index_granularity_for_block);
return index_granularity_for_block;
}
- 这里我们可以看到计算 Index Granularity 的细节
- 当配置了 index_granularity_bytes 时,会按照 block.bytes() 统计的 Block 字节数来决定一个 Granular 具体说多少行
代码清单: src/Storages/MergeTree/IMergeTreeDataPartWriter.cpp
Block getBlockAndPermute(const Block & block, const Names & names, const IColumn::Permutation * permutation)
{
Block result;
for (size_t i = 0, size = names.size(); i < size; ++i)
{
const auto & name = names[i];
result.insert(i, block.getByName(name));
/// Reorder primary key columns in advance and add them to `primary_key_columns`.
if (permutation)
{
auto & column = result.getByPosition(i);
// 执行对 Column 的排序
column.column = column.column->permute(*permutation, 0);
}
}
return result;
}
column->permute(...)执行对 Column 的排序
P2.5.4 MergeTreeDataPartWriterWide::writeColumn
代码清单: src/Storages/MergeTree/MergeTreeDataPartWriterWide.cpp
void MergeTreeDataPartWriterWide::writeColumn(
const NameAndTypePair & name_and_type,
const IColumn & column,
WrittenOffsetColumns & offset_columns,
const Granules & granules)
{
// 省略 ...
if (inserted)
{
ISerialization::SerializeBinaryBulkSettings serialize_settings;
serialize_settings.getter = createStreamGetter(name_and_type, offset_columns);
serialization->serializeBinaryBulkStatePrefix(serialize_settings, it->second);
}
// 省略 ...
for (const auto & granule : granules)
{
// 省略 ...
// 写入单个 Granule 到 xxx.bin
writeSingleGranule(
name_and_type,
column,
offset_columns,
it->second,
serialize_settings,
granule
);
if (granule.is_complete)
{
// 省略 ...
for (const auto & mark : marks_it->second)
// 写入 Column 对应的 .mrk 索引文件
flushMarkToFile(mark, index_granularity.getMarkRows(granule.mark_number));
// 省略 ...
}
// 省略 ...
}
// 省略 ...
}
- 对 Column 中的每个 granule 分别执行
writeSingleGranule()写入 Column 内容到.binflushMarkToFile()写入 Column.mrk索引- granule 是存储/读取的基础单位
- 细节如下图所示

代码清单: src/Storages/MergeTree/MergeTreeDataPartWriterWide.cpp
void MergeTreeDataPartWriterWide::writeSingleGranule(
const NameAndTypePair & name_and_type,
const IColumn & column,
WrittenOffsetColumns & offset_columns,
ISerialization::SerializeBinaryBulkStatePtr & serialization_state,
ISerialization::SerializeBinaryBulkSettings & serialize_settings,
const Granule & granule)
{
// 获得字段对应的序列化实例
const auto & serialization = data_part->getSerialization(name_and_type);
// 调用 ISerialization::serializeBinaryBulk() 完成字段序列化
serialization->serializeBinaryBulkWithMultipleStreams(column, granule.start_row, granule.rows_to_write, serialize_settings, serialization_state);
// 省略 ...
}
getSerialization()得到数据类型对应的 serialization- 调用 ISerialization::serializeBinaryBulk() 完成序列化
- 下面以 String 类型为例
代码清单: src/DataTypes/Serializations/SerializationString.cpp
void SerializationString::serializeBinaryBulk(const IColumn & column, WriteBuffer & ostr, size_t offset, size_t limit) const
{
const ColumnString & column_string = typeid_cast<const ColumnString &>(column);
const ColumnString::Chars & data = column_string.getChars(); // 将所有字符串拼接起来
const ColumnString::Offsets & offsets = column_string.getOffsets(); // 可用来得到每个 String 在 data 中的 Offset
// 在实际存储中,offsets 为 Maps i'th position to offset to i+1'th element. Last offset maps to the end of all chars (is the size of all chars).
// 省略 ...
if (offset == 0)
{
UInt64 str_size = offsets[0] - 1;
writeVarUInt(str_size, ostr); // 写入第一个 String 的长度
ostr.write(reinterpret_cast<const char *>(data.data()), str_size); // 写入第一个 String 内容
++offset;
}
for (size_t i = offset; i < end; ++i)
{
UInt64 str_size = offsets[i] - offsets[i - 1] - 1;
writeVarUInt(str_size, ostr); // 继续写入后续 String 的长度
ostr.write(reinterpret_cast<const char *>(&data[offsets[i - 1]]), str_size); // 继续写入后续 String 的内容
}
}
- 我们可以看到
ColumnString中的多个 String Value 是连续组织的,使用 Offsets 来记录不同的 String 边界。 - 序列化时,对每个
String Value先写入长度,再写入 String 内容,这是最常用的 String 序列化方法 - writeVarUInt() 并非固定写入 4 字节,而是 variable-length quantity(VLQ) 变长编码方式,每个字节最高位标识是否还有后续字节,细节示例如下图
- 注意这里是写入到 WriteBuffer 中,真正落地到磁盘还会经过一次压缩

至此我们已经从插入数据最上层的 InterpreterInsertQuery,到了最底层的 SerializationString::serializeBinaryBulk 实现 String 的序列化。剩下的细节还有很多,例如 Compact 格式、各种 Index、Prejection、renameTempPartAndAdd 的实现等,大家可以对照源码进一步探索。
优秀源码赏析
这里着重介绍实现优秀的源码。
代码清单: src/Interpreters/sortBlock.cpp
bool isAlreadySorted(const Block & block, const SortDescription & description)
{
// 省略 ...
/** If the rows are not too few, then let's make a quick attempt to verify that the block is not sorted.
* Constants - at random.
*/
// 抽样 10 个数(等距离分散采样),快速检查是否排好序
// 如果已经排好序,只需要 O(N) 的代价即可完成排序
// 如果尚未排好序,这十个数的检查代价也可以接受
// 这是一个非常好的面向常见特殊场景优化的例子
static constexpr size_t num_rows_to_try = 10;
if (rows > num_rows_to_try * 5)
{
for (size_t i = 1; i < num_rows_to_try; ++i)
{
size_t prev_position = rows * (i - 1) / num_rows_to_try;
size_t curr_position = rows * i / num_rows_to_try;
if (less(curr_position, prev_position))
return false;
}
}
for (size_t i = 1; i < rows; ++i)
if (less(i, i - 1))
return false;
return true;
}
- 面向特殊场景优化,是贯穿 ClickHouse 各个时期的开发哲学
- 类似的面向场景优化还有:
uniqCombined聚合函数、quantileTiming聚合函数 等等
代码清单: src/Disks/LocalDirectorySyncGuard.cpp
LocalDirectorySyncGuard::~LocalDirectorySyncGuard()
{
try
{
#if defined(OS_DARWIN)
if (fcntl(fd, F_FULLFSYNC, 0))
throwFromErrno("Cannot fcntl(F_FULLFSYNC)", ErrorCodes::CANNOT_FSYNC);
#else
if (-1 == ::fdatasync(fd))
throw Exception("Cannot fdatasync", ErrorCodes::CANNOT_FSYNC);
#endif
if (-1 == ::close(fd))
throw Exception("Cannot close file", ErrorCodes::CANNOT_CLOSE_FILE);
}
catch (...)
{
tryLogCurrentException(__PRETTY_FUNCTION__);
}
}
LocalDirectorySyncGuard在析构函数执行时完成对目录的 Sync 刷写- new LocalDirectorySyncGuard 对象后,超出变量作用域即可自动调用析构函数完成IO同步到磁盘
- 与 Golang 语言的 Defer 语句有异曲同工之妙
4. 总结
MergeTree Write-path 过程中的耗时主要分布于:
- 对 Partition By 相关字段进行 Hash 映射为 partition
- 对 Block 按照 Sort By 子句排序
- 统计 TTL 信息
- 序列化/写入数据数据到磁盘
- 写入 Primary、Secondary 索引
性能建议:
- 如果想要提高写入性能,可以提前对数据按照 MergeTree SORT BY 进行排序后再插入
- 尽量不在一次数据插入中涉及两个 Partition,Block 中的数据会按照 Partition 拆分并且分多个批次顺序写入
- ClickHouse 为支持 TTL 功能,在数据插入时做了大量的工作
- ClickHouse 的一次数据插入需要做大量的工作(后续还有后台Merge),因此降低插入频率,一次尽可能插入数万条数据以上 (考虑到索引粒度默认已经是 8192)
5. 参考文献
- Dremel: Interactive Analysis of Web-Scale Datasets
- The Log-Structured Merge-Tree (LSM-Tree)
- Dive into ClickHouse Storage System
- variable-length quantity(VLQ)
- CMU 15-445/645 Database System
- CMU 15-721 Advanced Database Systems