1. 背景
数据库从存储引擎中读取数据,通常称之为 Scan 操作。
通常 Scan 需要考虑到以下因素:
- 是否使用索引 ?使用哪些索引 ?
- 是否并发读取 ?
- 列式存储如何实现 Predicate Pushdown ?
索引
对于 OLTP 数据库,普遍使用的索引是 B-Tree,而 Postgres 面向特殊场景还支持一些额外的索引类型,如 GiST, GIN。
而 OLAP 数据库通常会使用粗粒度的二级索引,因为 OLAP 数据库都假定需要读取非常多的数据做计算,所以索引没有必要非常精细,通常由下面几种索引类型:
- 最常用的
min-max统计 - 部分引擎(如 ORC)支持
bloom-filter - ClickHouse 支持的索引类型相对来说比较丰富,例如额外支持:
set,ngrambf_v1。
Parallel Scan
OLAP 查询因为涉及大量的数据 Scan,I/O 势必会成为瓶颈,所以需要充分利用 I/O 带宽,而 Parallel Scan 是一种计算机多核化趋势下的合理解决方案。
ClickHouse 使用多线程读取模型并行读取数据,后文会有更详细的源码解析。
业界也有其他数据库支持 Parallel Scan,如 Postgres 在 9.6 版本新增 Parallel Sequential Scan 特性,Kudu 同样支持 Parallel Scan,而对于 Spark/Flink 等大数据计算引擎,Parallel Scan 是默认的模式(不同的数据源实现可能有差异)。
Predicate Pushdown
将 SQL 查询中的 Where 部分,下推到存储引擎执行,这个过程称之为 Predicate Pushdown (谓词下推)。
但在列式存储引擎面前有一个额外问题需要考虑,如何高效执行 Predicate Pushdown ?
- 方案 1: 读取所有 Column,再执行 Filter
- 方案 2: 先读取 Filter 相关的 Column,Filter 后识别哪些 Row Range 不用再读取,然后读取剩余 Column
方案 2 相比方案 1 潜在上可以提升性能,因为可以减少冗余 IO. 但是 ClickHouse 使用的方案 1, 但是有简单的判空 Skip.
2. MergeTree Read-Path 概述
简单来讲,MergeTree Read Path 包含以下几个阶段:
此为笔者自己总结,非官方资料
- 阶段 1: Analysis, 确定读哪些 data part,哪些 range
- 阶段 2: Parallel, 并行化,拆分成 N 个线程执行
- 阶段 3: Read, 反序列化读取数据
如下图所示:

3. MergeTree Read-Path 源码解析
MergeTree Read-Path 整体调用链路要比 Write-Path 长的多。 额外新增 Call Tree 一节辅助想要看更多源码细节的读者快速找到对应的函数。
Call Tree
- InterpreterSelectQuery::InterpreterSelectQuery
- MergeTreeWhereOptimizer::optimize
- InterpreterSelectQuery::executeImpl
- InterpreterSelectQuery::executeFetchColumns
- MergeTreeDataSelectExecutor::read
- MergeTreeDataSelectExecutor::readFromParts
- ReadFromMergeTree::initializePipeline
- ReadFromMergeTree::getAnalysisResult
- ReadFromMergeTree::selectRangesToRead
- MergeTreeDataSelectExecutor::filterPartsByPartition
- MergeTreeDataSelectExecutor::filterPartsByPrimaryKeyAndSkipIndexes
- MergeTreeDataSelectExecutor::markRangesFromPKRange
- MergeTreeDataSelectExecutor::filterMarksUsingIndex
- ReadFromMergeTree::spreadMarkRangesAmongStreams
- ReadFromMergeTree::read
- ReadFromMergeTree::readFromPool
- MergeTreeReadPool
- MergeTreeReadPool::fillPerThreadInfo
- Parallel Thread: MergeTreeThreadSelectProcessor
- MergeTreeBaseSelectProcessor::generate
- MergeTreeReadPool::getTask
- MergeTreeBaseSelectProcessor::readFromPartImpl
- MergeTreeRangeReader::read
- MergeTreeRangeReader::startReadingChain
- MergeTreeRangeReader::executePrewhereActionsAndFilterColumns
- MergeTreeRangeReader::continueReadingChain
- MergeTreeReaderWide::readRows
- MergeTreeReaderWide::readData
- SerializationString DB::deserializeBinarySSE2P1: Analysis
Analysis 阶段: 分析需要读取哪些 Part,以及 Part 中哪些部分需要读取。
P1.1 自动添加 PreWhere
关于 PreWhere 的更多介绍见 PREWHERE Clause.
PreWhere 是 ClickHouse 扩展的 SQL 子句,其在 Where 子句之前执行。 通常情况下,你并不需要显示写明 PreWhere,ClickHouse 会自动将合适的 Where 子句条件转移到 PreWhere 子句下。
void MergeTreeWhereOptimizer::optimize(ASTSelectQuery & select) const
{
// MK: 如果已经手动定义过 PreWhere,将不会进行自动的 PreWhere 分析
if (!select.where() || select.prewhere())
return;
UInt64 total_size_of_moved_conditions = 0;
/// Move condition and all other conditions depend on the same set of columns.
auto move_condition = [&](Conditions::iterator cond_it)
{
prewhere_conditions.splice(prewhere_conditions.end(), where_conditions, cond_it);
total_size_of_moved_conditions += cond_it->columns_size;
// MK: ...
};
/// Move conditions unless the ratio of total_size_of_moved_conditions to the total_size_of_queried_columns is less than some threshold.
while (!where_conditions.empty())
{
/// Move the best condition to PREWHERE if it is viable.
// MK: 选择数据量最小的 column
auto it = std::min_element(where_conditions.begin(), where_conditions.end());
bool moved_enough = false;
if (total_size_of_queried_columns > 0)
{
/// If we know size of queried columns use it as threshold. 10% ratio is just a guess.
moved_enough = total_size_of_moved_conditions > 0
&& (total_size_of_moved_conditions + it->columns_size) * 10 > total_size_of_queried_columns;
}
// MK: ...
if (moved_enough)
break;
move_condition(it);
}
// MK: ...
// MK: 可以打开 Debug 日志,观察哪些 column 被自动移入 PREWHERE
LOG_DEBUG(log, "MergeTreeWhereOptimizer: condition \"{}\" moved to PREWHERE", select.prewhere());
}
- 当 SQL 语句已经提前声明了 PreWhere 时,ClickHouse 将不再进行 PreWhere 优化分析,因此有足够把握比 ClickHouse 做的好的时候再手动添加 PreWhere
- 尽量将 size 比较小的 Where 谓词相关的 Columns 移动到 PreWhere
- 移入 PreWhere 的 Columns 总 size 不大于整体的 10%, 此值为经验值并且不可以通过 settings 配置
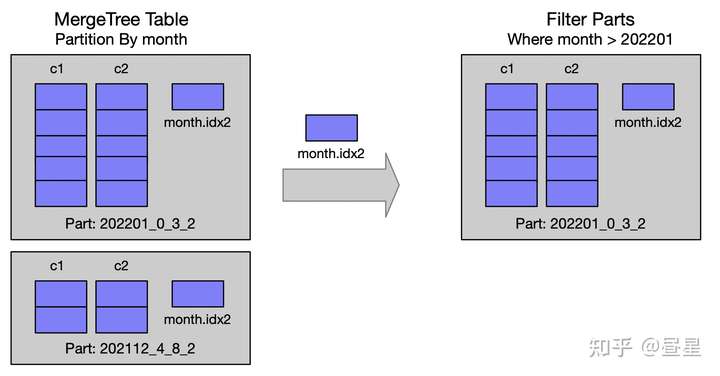
P1.2 通过 Partition 筛选 Parts
每次插入都会生成新的 Part,Part 会在后台定期 Merge,仅在同一个 Partition 分区的 Part 才可以 Merge,Part 在达到一个预置的大小(默认 150GB)会停止 Merge。 因此 MergeTree 表是由多个 Partition 构成的,filterPartsByPartition 函数用来筛选查询需要的 Part。
void MergeTreeDataSelectExecutor::filterPartsByPartition(
MergeTreeData::DataPartsVector & parts,
... )
{
// MK: ...
minmax_idx_condition.emplace(
query_info, context, minmax_columns_names,
data.getMinMaxExpr(partition_key, ExpressionActionsSettings::fromContext(context)));
partition_pruner.emplace(metadata_snapshot, query_info, context, false /* strict */);
selectPartsToRead( ... );
// MK: ...
}
void MergeTreeDataSelectExecutor::selectPartsToRead(
MergeTreeData::DataPartsVector & parts,
... )
{
MergeTreeData::DataPartsVector prev_parts;
std::swap(prev_parts, parts);
for (const auto & part_or_projection : prev_parts)
{
// MK: ...
if (minmax_idx_condition && !minmax_idx_condition->checkInHyperrectangle(
part->minmax_idx->hyperrectangle, minmax_columns_types).can_be_true)
continue;
if (partition_pruner)
{
if (partition_pruner->canBePruned(*part))
continue;
}
parts.push_back(part_or_projection);
}
}
- 对于所有的 Part,遍历并检查是否可以 Skip
- 检查依据是 Part 在写入时,记录的 Partition 相关 Column 的 min-max 索引
- 更多细节可查看源码
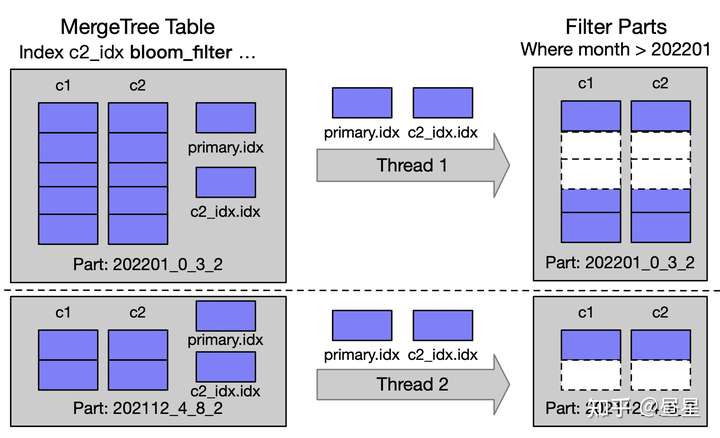
P1.3 根据 PK/Index 筛选 Range
Primary key 是有序的,可以根据 Primary key 来筛选相关的 Range。 此外,ClickHouse 支持 Bloom-Filter、Min-Max、Set 等粗粒度二级索引,用来过滤 Granule。
struct MarkRange
{
size_t begin;
size_t end;
// MK: ...
};
using MarkRanges = std::deque<MarkRange>;
struct RangesInDataPart
{
MergeTreeData::DataPartPtr data_part;
size_t part_index_in_query;
MarkRanges ranges;
// MK: ...
};
using RangesInDataParts = std::vector<RangesInDataPart>;
- MarkRanges 及 RangesInDataParts 的定义
- RangesInDataParts 标记出在每个 Part,有哪些 MarkRanges 是需要读取的
RangesInDataParts MergeTreeDataSelectExecutor::filterPartsByPrimaryKeyAndSkipIndexes (
MergeTreeData::DataPartsVector && parts,
...)
{
// MK: ...
auto process_part = [&](size_t part_index)
{
auto & part = parts[part_index];
if (metadata_snapshot->hasPrimaryKey())
// MK: 根据 primary key 筛选 part 下的 ranges
ranges.ranges = markRangesFromPKRange(part, metadata_snapshot, key_condition, settings, log);
else if (total_marks_count)
ranges.ranges = MarkRanges{MarkRange{0, total_marks_count}};
// MK: ...
for (auto & index_and_condition : useful_indices)
{
// MK: 根据 secondary index 筛选 part 下的 ranges
ranges.ranges = filterMarksUsingIndex( ... );
}
// MK: ...
};
/// Parallel loading of data parts.
ThreadPool pool(num_threads);
for (size_t part_index = 0; part_index < parts.size(); ++part_index)
pool.scheduleOrThrowOnError([&, part_index, thread_group = CurrentThread::getGroup()]
{
// MK: ...
process_part(part_index);
});
return parts_with_ranges;
}
- 多线程并行处理多个 Part (有最大并发限制)
- markRangesFromPKRange 根据 Primary Key 筛选 Part Ranges
- filterMarksUsingIndex 根据 Secondary Indexs 筛选 Part Ranges
- markRangesFromPKRange 为纯内存操作,
Primary Key已经 Cache 在内存中 - filterMarksUsingIndex 需要有 Disk IO
P2: Parallel
Parallel 阶段: 将读取任务拆解为 N 个可并行的读取任务,即为 Parallel Scan.
首先,我们考虑一个问题,如何并行扫描效率是最高的 ?和下列因素相关:
- 并行度, 也就是同时有多少线程/进程可以用来扫描数据
- 磁盘总 IO 带宽
- IO 次数
ClickHouse 在读取任务的规划上,做了下述决策来提升性能:
- (并行度) 尽可能利用 CPU 资源,查询并发默认为物理核数。
- (IO 带宽) 分散线程负载到多个磁盘,尽可能充分利用磁盘带宽
- (IO 次数) 读取时不留“小尾巴”,如果一个 Part 内只剩少量数据时,一次读取完
- (Steal Tasks) 当一些线程提前完成读取任务时,可以执行预分配给其他线程的任务
下面我们可以看下实现细节。
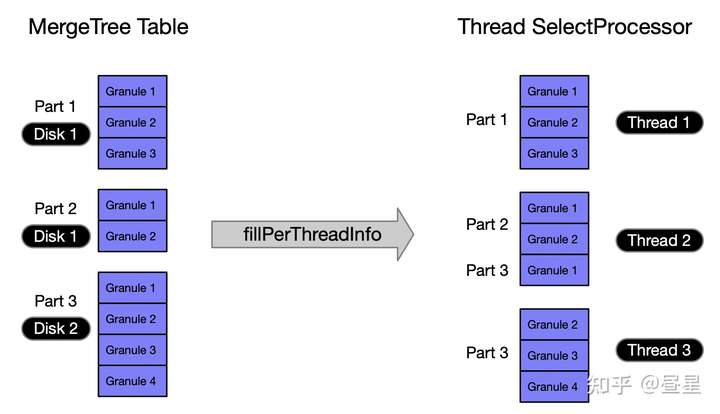
P2.1: 将读取任务分配到多个线程
void MergeTreeReadPool::fillPerThreadInfo(
const size_t threads, const size_t sum_marks, std::vector<size_t> per_part_sum_marks,
const RangesInDataParts & parts, const size_t min_marks_for_concurrent_read)
{
// MK: 类型定义及初始化 ...
{
// MK: 将 part 按 Disk 分组到 parts_per_disk
// MK: ...
for (auto & info : parts_per_disk)
parts_queue.push(std::move(info.second));
}
const size_t min_marks_per_thread = (sum_marks - 1) / threads + 1;
// MK: 按 Disk 分配线程负载,最大化磁盘 IO 带宽利用率
for (size_t i = 0; i < threads && !parts_queue.empty(); ++i)
{
auto need_marks = min_marks_per_thread;
while (need_marks > 0 && !parts_queue.empty())
{
// MK: ...
/// Get whole part to read if it is small enough.
if (marks_in_part <= need_marks)
{
// MK: 整个 Part 作为当前 Task
// 但不会继续塞入下个 Part
}
else
{
/// Loop through part ranges.
while (need_marks > 0)
{
// MK: ...
// MK: 在单个 Part 内部,持续向 Task 内添加 Mark 直到到达每个 Task 的 need_marks
ranges_to_get_from_part.emplace_back(range.begin, range.begin + marks_to_get_from_range);
// MK: ...
if (range.begin == range.end)
part.ranges.pop_front();
// MK: ...
need_marks -= marks_to_get_from_range;
}
}
threads_tasks[i].parts_and_ranges.push_back({ part_idx, ranges_to_get_from_part });
threads_tasks[i].sum_marks_in_parts.push_back(marks_in_ranges);
if (marks_in_ranges != 0)
remaining_thread_tasks.insert(i);
}
// MK: ...
}
}
- 将所有 Part 按物理存储磁盘排序
- 按序将磁盘负载分散到 N 个线程,这样可减少线程间的 IO 竞争
P2.2: 获取当前线程执行的 Task
并不会将线程需要完成的所有任务初始时全部分配,而是每次仅会分配一个小量级的数据读取任务。
通过参数: merge_tree_min_rows_for_concurrent_read / merge_tree_min_bytes_for_concurrent_read 配置读取的数据量级。

MergeTreeReadTaskPtr MergeTreeReadPool::getTask(const size_t min_marks_to_read, const size_t thread, const Names & ordered_names)
{
// MK: 无任务时直接返回 nullptr ...
/// Steal task if nothing to do and it's not prohibited
auto thread_idx = thread;
if (!tasks_remaining_for_this_thread)
{
auto it = remaining_thread_tasks.lower_bound(backoff_state.current_threads);
// Grab the entire tasks of a thread which is killed by backoff
if (it != remaining_thread_tasks.end())
{
// MK: 先检查是否还有剩下的可以执行的任务 ...
}
else // Try steal tasks from the next thread
{
// MK: 当前线程没有任务可以执行时,执行其他线程的 Task (Steal Tasks)
it = remaining_thread_tasks.upper_bound(thread);
if (it == remaining_thread_tasks.end())
it = remaining_thread_tasks.begin();
thread_idx = *it;
}
}
auto & thread_tasks = threads_tasks[thread_idx];
// MK: ...
return std::make_unique<MergeTreeReadTask>(
part.data_part, ranges_to_get_from_part ...);
}
- getTask() 函数参数 min_marks_to_read, 通过 setting 配置 merge_tree_min_rows_for_concurrent_read / merge_tree_min_bytes_for_concurrent_read 计算得到
- merge_tree_min_rows_for_concurrent_read 默认值为 163840,大约是 20 个 Granule。
- 如果当前线程已经没有剩余 Task,则分配其他线程的待执行任务 (Steal Tasks)
P3: Read
分配好每个线程的任务后,就可以开始真正读取数据了。
从宏观结构上,ClickHouse 将读取分成了两部分
此为笔者自己总结,非官方资料
Read Pre-Where Columns, 先读取 Pre-Where 相关 ColumnsRead Remaining Columns, 再读取剩余 Columns
Read Pre-Where Columns 过程中,还会对数据进行 Filter,如果 Filter 后无数据,便不会进行后续的 Read Remaining Columns 步骤。
P3.1: Read Pre-Where Columns
MergeTreeRangeReader::ReadResult MergeTreeRangeReader::read(size_t max_rows, MarkRanges & ranges)
{
// MK: ...
if (prev_reader)
{
// MK: 分支 1
// MK: 如果有 pre where 条件,先把 pre where 涉及的字段读出来
read_result = prev_reader->read(max_rows, ranges);
// MK: 再把除了 pre where 剩下的字段读出来
Columns columns = continueReadingChain(read_result, num_read_rows);
// MK: ...
if (has_columns)
{
// MK: 如果有 Filter,就地执行 filter ...
if (read_result.getFilter())
filterColumns(columns, read_result.getFilter()->getData());
}
// MK: 将上面读到的两部分字段合并...
for (auto & column : columns)
read_result.columns.emplace_back(std::move(column));
}
else
{
// MK: 分支 2
read_result = startReadingChain(max_rows, ranges);
// MK: ...
}
// MK: 分支 3
// MK: 如果有 pre where 条件,构建 filter column
// MK: pre where 相关的 columns 就地执行 filter
executePrewhereActionsAndFilterColumns(read_result);
return read_result;
}
- 这里逻辑稍微有一点绕,读取
Pre-Where相关 Columns 时,仅会走分支 2,分支 3 - 而读取完
Pre-Where后,仅会走分支 1,continueReadingChain函数读取剩下的 Columns - executePrewhereActionsAndFilterColumns 逻辑不再详述,感兴趣可以去阅读源码
P3.3: Read Rows 具体实现
下面是读取的具体实现。
readRows() 函数读取范围行数内的所有列的数据。 分别对每一列数据,使用对应的反序列化方法进行读取。
size_t MergeTreeReaderWide::readRows(
size_t from_mark, size_t current_task_last_mark, bool continue_reading, size_t max_rows_to_read, Columns & res_columns)
{
try
{
// MK: ...
for (size_t pos = 0; pos < num_columns; ++pos, ++name_and_type)
{
auto column_from_part = getColumnFromPart(*name_and_type);
// MK: ...
readData(
column_from_part, column, from_mark, continue_reading, current_task_last_mark,
max_rows_to_read, cache, /* was_prefetched =*/ !prefetched_streams.empty());
// MK: ...
}
}
// MK: ...
return read_rows;
}
void MergeTreeReaderWide::readData(...)
{
// MK: ...
auto serialization = data_part->getSerialization(name_and_type);
// MK: ...
serialization->[[CH.ISerialization::deserializeBinaryBulkWithMultipleStreams]](column, max_rows_to_read, deserialize_settings, deserialize_state, &cache);
}
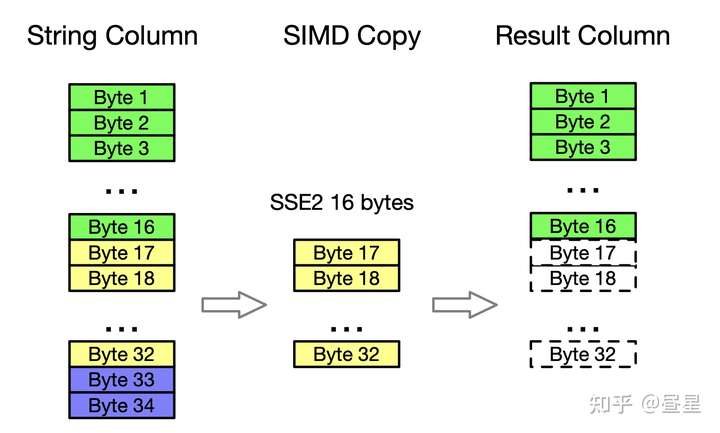
下面是 String 类型的反序列化代码解析。
void SerializationString::deserializeBinaryBulk(IColumn & column, ReadBuffer & istr ...) const
{
// MK: ...
// MK: 读取 String 类型 Column 时,开启了 SSE2 指令集相关优化
if (avg_chars_size >= 64)
deserializeBinarySSE2<4>(data, offsets, istr, limit);
else if (avg_chars_size >= 48)
deserializeBinarySSE2<3>(data, offsets, istr, limit);
else if (avg_chars_size >= 32)
deserializeBinarySSE2<2>(data, offsets, istr, limit);
else
deserializeBinarySSE2<1>(data, offsets, istr, limit);
}
template <int UNROLL_TIMES>
static NO_INLINE void deserializeBinarySSE2(ColumnString::Chars & data, ColumnString::Offsets & offsets, ReadBuffer & istr, size_t limit)
{
size_t offset = data.size();
for (size_t i = 0; i < limit; ++i)
{
if (istr.eof())
break;
UInt64 size;
readVarUInt(size, istr);
offset += size + 1;
offsets.push_back(offset);
data.resize(offset);
if (size)
{
#ifdef __SSE2__
/// An optimistic branch in which more efficient copying is possible.
if (offset + 16 * UNROLL_TIMES <= data.capacity() && istr.position() + size + 16 * UNROLL_TIMES <= istr.buffer().end())
{
const __m128i * sse_src_pos = reinterpret_cast<const __m128i *>(istr.position());
const __m128i * sse_src_end = sse_src_pos + (size + (16 * UNROLL_TIMES - 1)) / 16 / UNROLL_TIMES * UNROLL_TIMES;
__m128i * sse_dst_pos = reinterpret_cast<__m128i *>(&data[offset - size - 1]);
while (sse_src_pos < sse_src_end)
{
// MK: _mm_storeu_si128 / _mm_loadu_si128 为 C++ 编译器提供的 SIMD 内置函数
// _mm_loadu_si128 -> SSE2 指令 MOVDQU
// _mm_storeu_si128 -> SSE2 指令 MOVDQU (底层对应于相同的 CPU 指令)
for (size_t j = 0; j < UNROLL_TIMES; ++j)
_mm_storeu_si128(sse_dst_pos + j, _mm_loadu_si128(sse_src_pos + j));
sse_src_pos += UNROLL_TIMES;
sse_dst_pos += UNROLL_TIMES;
}
istr.position() += size;
}
else
#endif
{
// MK: 不支持SSE2/尾部未对齐时的保底复制方案
istr.readStrict(reinterpret_cast<char*>(&data[offset - size - 1]), size);
}
}
data[offset - 1] = 0;
}
}
- String 类型的反序列化做了 SIMD 优化 (SSE2 指令集)
- ClickHouse 广泛使用 SIMD 指令集来提升热点函数性能
- 此处为较为简单的 SIMD 应用场景: 快速内存复制 (一次性复制更多字节内存)
- 对未对齐的尾部元素及不支持 SSE2 指令集的场景,有保底处理
4. 总结
至此我们已经完成了从查询时候的 Part Ranges 分析,到最终反序列化 String 类型的 Column 读取到内存中的过程。 MergeTree Read Path 基础的流程已全面覆盖,以下细节出于篇幅未展开,感兴趣可以继续深入源码:
- MergeTree projection
- Partition / Primary Key / Secondary Index 的实现细节
MergeTree Write-path 过程中的耗时主要分布于:
- 读取二级索引判断需要读取的 Part Ranges
- 读取数据时的 Disk IO
- 将数据反序列化
性能建议:
- 避免 Part 总数过多,尽管 ClickHouse 会启动多个线程分析 Part 索引,但难免有木桶效应,因此不要让 Part 总数过多,把查询时间过多浪费在分析 Part Range 上
- 使用多块磁盘,ClickHouse 可以充分利用磁盘 IO 带宽 (建议使用 RAID)
- 注意二级索引的使用,索引不是越多越好,如果加的索引不能有效地减少Scan数据量,会有查询 overhead 浪费性能
- PreWhere 子句谨慎手动填写,除非确认自己可以做的更好。
5. 参考文献
- Dive into ClickHouse Storage System
- Kudu: Storage for Fast Analytics on Fast Data
- Postgresql Documentation
- CMU 15-445/645 Database System
- CMU 15-721 Advanced Database Systems